Запись текстовой информации
Запись текстовой информации
Код ОГЭ по информатике: 2.2.2. Запись текстовой информации с использованием различных устройств
Текстовая информация — информация, выраженная с помощью естественных и формальных языков в письменной или печатной форме.
Для ручного ввода текстовой информации чаще всего используются клавиатура и мышь. Для голосового ввода — микрофон вместе с соответствующими современными программами распознавания голоса.
Сканирование
Для оптического ввода в компьютер и преобразования в электронную форму текстовые документы и изображения (фотографии, рисунки, слайды) необходимо оцифровать. Технологический процесс оцифровки, в результате которого создается графический образ бумажного документа, называется сканированием. Устройства, способные к оцифровке изображений, — планшетный, листовой, слайдовый и барабанный сканеры, цифровые камеры, платы ввода видеоданных и др.
Графический файл, полученный в результате сканирования, хранит растровое изображение исходного документа (состоящее из точек).
После обработки документа сканером получается графическое изображение документа (графический образ), т. е. набор разноцветных точек. Сканированный текст нельзя редактировать, выбрать из него фрагмент и т. п. Для того, чтобы редактирование стало возможным, следует перевести сканированный текст из графического в текстовый формат. Программы, способные выполнять эту операцию, называются программами распознавания текста, или OCR (англ. Optical Character Recognition — оптическое распознавание символов).
Проблема распознавания текста является весьма сложной. Современные алгоритмы распознавания текста не ориентируются ни на конкретный шрифт, ни на конкретный алфавит. Большинство программ способно распознавать текст на нескольких языках, представленный в различных формах (например, таблицах, нескольких колонках) и с различным качеством печати.
Лидером среди программ распознавания, которые поддерживают работу с русским языком, является FineReader российской компании ABBYY. Программа производит распознавание текста более чем со 180 языков, открывает файлы многих графических форматов (TIFF, JPG, PFD, PNG, DjVu и др.). Встроена возможность распознавания изображений с цифровых фотоаппаратов.
Еще одна система — OCR CuneiForm — бесплатная программа сканирования и распознавания текста российской компании Cognitive Technologies. Она обеспечивает распознавание текста с сохранением исходного вида документов на более чем 20 языках, в том числе русском, а также распознавание смешанного русско–английского текста.
Текстовые документы предпочтительнее сканировать из системы распознавания, а не с помощью запуска «родной» программы сканера, поскольку та все равно будет вызвана для процесса сканирования, а после его завершения документ предстоит распознавать.
Рассмотрим процесс распознавания документов на примере программы ABBYY FineReader.
При установке программы на компьютер команды ее запуска добавляются во многие контекстные меню. Можно открыть изображение документа прямо из окна Проводника или Моего компьютера, выбрав из контекстного меню команду Открыть с помощью ABBYY FineReader.
Также при установке программа интегрируется в приложения MS Office. В таких программах, как MS Word, MS Exсel, появится панель ABBYY FineReader. Для распознавания документов непосредственно из MS Word или MS Excel нужно нажать кнопку этой панели, проверить в диалоговом окне установленные опции и нажать кнопку Старт. Будет запущена программу FineReader, а распознанный ею текст будет передан обратно в MS Word или MS Exсel.
В стартовом окне FineReader содержится список наиболее распространенных сценариев обработки документов (последовательностей операций). Например, сценарий Сканировать в PDF содержит набор операций: «отсканировать — распознать — сохранить в PDF». Наиболее часто используется сценарий Сканировать в Microsoft Word — он предлагает отсканировать документ, распознать его содержимое и передать в текстовый редактор Word. Можно выполнить требуемые действия и без выбора сценария — запуская самостоятельно нужные этапы.
После запуска сценария на экране появляется панель его выполнения, список шагов сценария, а также подсказки и предупреждения.
Слева на боковой панели (1) видны значки (образы) страниц распознаваемого документа и ход распознавания. Выбранная в этой панели страница отображается в основной части окна слева (2). На этом изображении программа автоматически выделяет области с текстом, картинками, таблицами. К каждой из них будут применены различные методы распознавания.
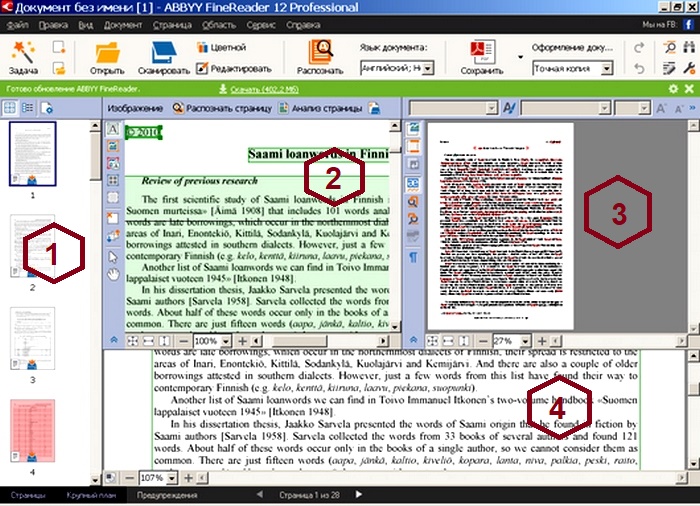
При желании пользователь может выбрать язык документа в левой панели. Для многоязычных документов можно указать несколько языков. Но это делать вовсе не обязательно — программа может определить язык автоматически.
Для запуска распознавания выбранной страницы следует нажать кнопку Распознать вверху окна Изображение (2) или выбрать команду меню Документ / Распознать документ. Если требуется распознать сразу все страницы документа — в выпадающем списке кнопки Распознать имеется команда Распознать документ.
Результат распознавания будет отображен в основной части программы справа — в панели Текст (3). В ней можно отредактировать документ, исправить замеченные ошибки и нераспознанные символы. При установке курсора в панели Текст на какое–либо слово — в панели Крупный план (4) в нижней части экрана показывается увеличенное изображение слова.
Неточно распознанные символы (в правильности распознавания которых FineReader не уверен) будут выделены цветом. Такие слова можно проверить с помощью встроенной проверки орфографии Проверка (вызывается с помощью основного меню Сервис/Проверка). При этом показывается ошибочное слово, его изображение в документе и варианты замены.
Результаты распознавания можно сохранить в файл, передать в указанное приложение, скопировать в буфер обмена или отправить по электронной почте. Сохранить можно все страницы документа или только выбранные. Для сохранения документа служит кнопка Сохранить вверху окна Текст (3).
Конспект урока по информатике «Запись текстовой информации с использованием различных устройств».
Вернуться к Списку конспектов по информатике.